3行でまとめると
- 画像生成AIを使って踊ってみた動画を作った
- 題材はゾンビ・デ・ダンスとハトマスク
- 作り方と、試行錯誤を記録しておく

画像生成AIを使って踊ってみた動画を作った
- Tiktokでダンス動画を見ている
- 自分で踊れると面白いんだろうけどそれはムリ
- だったら踊ってみた動画を作るのはどうだろう?
- 画像生成AIで作った動画もでてきてるしできるんじゃなかろうか?
題材はゾンビ・デ・ダンスとハトマスク
- ユニバーサルスタジオジャパンのハロウィーン・ホラー・ナイトで使われている
- Tiktokでは秋頃からよく動画で流れてた動画
- いろんな方のダンスを見ることができて楽しい
- せっかくなので、ハトマスクをかぶせてみたらどうかと思った
- これやらなきゃもうちょっと楽だったかも?
- せっかくだからと、うっかりで人生80%くらいを消費している気がするが、それもまたヨシ
作り方と、試行錯誤を記録する
作り方
元になるダンス動画を画像生成AIを使って、ハトマスクのダンス動画に変換する
元になるダンス動画
- SNSに上がっている動画を使うのはよろしくないので、自前で用意する
- ダンスは踊れないので、MMDを使ってダンス動画を作ることにした
- 有志の方が公開しているモーション・モデルを使わせていただいた。ありがすぎる
- モーション
- モデル
- デフォルトマン Ver2.1
- animvmd.blogspot.com
できたのはこんな動画(背景はMMDで差し込んだ)

この部分だけでダンス動画を作ったことにはなるんだけども、画像生成AIを使いたいのでそこはあえて無視する。
画像生成AI
画像生成AIは、入力されたテキストを元に訓練済みのモデルを使って画像を生成する。
- 好みの画像を生成するために色んな工夫ができる
- 画風や風合い?を指定したり
- 人物のポーズや構図を指定したり
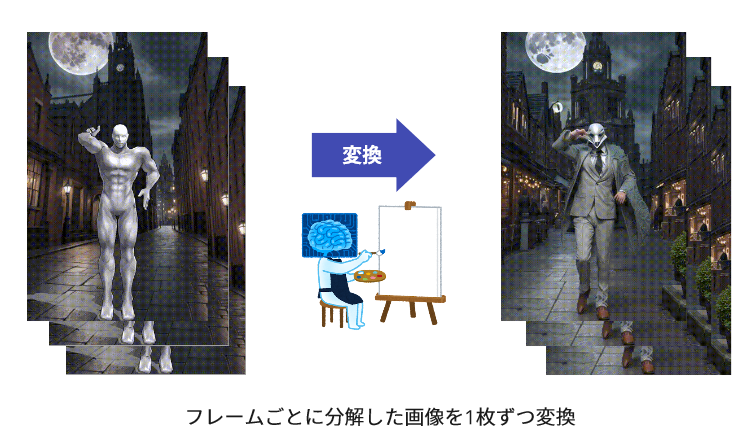
今回は画像生成AIを使って動画を作成するために以下のような方法を使った。めっちゃ力業。
32秒、481フレームの動画を50分程度で生成できる。
- 動画をフレームごとの画像に分割する
- 分割した画像を元にAIを使って画像を生成する
- ポーズや構図は元画像に合わせる
- 服装は好みのものにする (ハトマスクもかぶせる)
- 生成した動画をつなぎ合わせて動画に戻す!
今回使ったツールや設定などを紹介。
- 訓練済みのモデル
- DreamShaper v8
- ハトマスクを再現できるようにチューニングしたモデル (LoRAという)
- 以下の画像を使って学習をさせた
- 学習に使ったスクリプト
- 以下の画像を使って学習をさせた
- 画像生成AI用ツール (コードを書かなくても画像生成ができるありがたいもの)
- Stable Diffusion web UI
- mov2mov
- ControlNet for Stable Diffusion WebUI
- 使った設定
- (T.B.D) pnginfoを使って調べましょう

試行錯誤したこと
画像生成AI用ツールを何にするか?
以下の条件を満たすものを探した。
- GPUのメモリ12GB (RTX4070)で動作する
- 約30秒の動画を、なるべく高い解像度で (できれば800x1280)
- 作ったゾンビ・デ・ダンスの動画が32秒
- ダンスの再現性が高い
- ハトマスクっぽいものを再現したい
- ドンピシャは難しいのでそれっぽいものが出ればOK
比較したツールとプラグインは以下の通り。
Automatic1111 + AnimateDiff for Stable Diffusion WebUI
- 背景や人物の統一感は素晴らしい
- ただし、動画の解像度を上げるとメモリ不足で30秒の動画が作れない
- 320x512 あたりが精一杯だった
Automatic1111 + mov2mov
- 800x1280で30秒の動画を作ることができる
- ただしちらつきが多くなる = 背景や人物の統一感はそこそこ
ComfyUI + AnimateDiff for ComfyUI
- 512x816で30秒の動画を作ることができた
- AnimateDiffを使っているので、背景や人物の統一感も素晴らしい
- が、ハトマスクの再現度がイマイチ…orz
解像度、人物、動画の統一感からいうとComfyUIなのだが、ハトマスクの再現度がイマイチだったので、Automatic1111 + mov2mov を利用した。
巷にはもっともっとスゴいダンス動画があるので、近づけるように努力したいところだけど、その前に飽きそう…。